An essay on software product vs. software project development (vs. cloud development)
Introduction
In my world, software development can be split in two disciplines: project development and product development. There is surprisingly little literature on this specific topic (either that, or I didn’t find it), yet they are in my opinion very distinct. And even though a lot of software engineers are actually part of a software product development team rather than a project development team, most literature in software development is actually about project development. Even more: most tools and methodologies focus on software projects rather than products. Don’t believe me? Well then, open Visual Studio and create a new solution, and the first thing you add is… a project. Coincidence? I don’t believe it is. Since I recently encountered a number of situations where I had to explain the difference, I decided to write an article on the topic, and by doing so, maybe trigger some more documentation and tooling in favour of product development.
Before going into depth on the differences, I guess I should first define them to make sure we are on the same page. A project is a solution developed for one specific customer that has a certain set of requirements. A product is a solution developed and offered to multiple (possible) customers and which aims to solve a common problem for these customers.
As for my background: I’m part of a team that develops an omni-channel contact center product on a daily basis, but I’m also involved in some smaller projects, and, I’m currently also working on a cloud solution, so I’m experiencing all of them at the same time. But product development is a big part of it, and that for more than 15 years in the meantime. I want to make clear that the goal of this article isn’t to label them good or bad, or promote the one or the other. They are just wo different things that are both needed and useful and this is only an attempt to document them and point out the differences (and maybe give some hints to how and where life of the product developer can be made better).
To end this introduction, it must be clear that project vs. product development is not about websites vs. desktop applications. I’m convinced that in both project and product development, the solution can be a desktop application, a web application, a distributed application or something else or a combination of all of them.
Software project development
Projects are typically sold once, made once. As mentioned in the definition, they are tailor made software for a specific customer with specific requirements. The cost or price of the solution is the time estimated to develop these requirements, which, either you pay as salaries to your in-house development team, or you pay a software development company to do it for you.
An important part in project development, if not the most important part, are the customer requirements. And in my experience, the lack thereof, or the fact they change often during the development process. And that is ok, because most customers and sales people do not have the experience or knowledge to define all the requirements needed for a development team. And I’m not the only one that feels that we should live with this and accept this. That is why we today we prefer agile methodologies in project development. They enable us to quickly iterate and check with the (internal) customer, who will inevitable get more insights during this proces and update his requirements. But the process takes this into account and allows this to happen.
One thing that remains hard to avoid, even with an agile process, is the difference between estimated and actual time. Agile allows you to iterate quickly, find defects (in requirements or software) fast and respond to it. Agile allows you to keep a better view on where you are. But agile doesn’t help you to estimate a project, nor does it provide a method to finish on time. Most projects will require more time than anyone thought at the beginning. There have been many books written on this matter, and how you should try to avoid this, but a lot of projects are stil late. And to me, it actually makes sense: after all these years I learned that you can only estimate required time correct if you have done that particular kind of thing before. Since we define a project as a one time thing, it is a given fact you will be wrong in your time estimation. Software teams are also often called R&D teams, and I think this one-time thing is actually the Research part of the story. And as with a lot of research in a lot of other businesses (pharmaceuticals, chemistry, …) there is not much accurate time estimation possible. You start with a certain goal and then you work out a solution for which you have a certain direction, but no one will tell you when you’ll discover the next ground breaking drug that solves a certain cure. The same goes for software your write the first time.
The only project teams that succeed in giving correct estimations, are the project teams that make a similar solution for each customer. For example, marketing agencies that create public websites for there customers have a pretty good idea on the time needed to develop yet another Drupal website for their new customer. That’s because usually 80 or 90% has been done before, it’s just the content that changes. The other remaining percent might be very specific, but the slip this can cause is a lot smaller and can be easily compensated by overestimating a little. So the company is safe if it takes a few days more than expected, and the customer paid a little extra, but its usually a small amount compared to the rest so it really doesn’t matter. In all other cases, timing will be wrong if you make something the first time.
What surprises me every time, is that most managers and sales people that decide on projects, sell/buy these projects for a fixed price without identifying in which of the two before mentioned categories they fall. And if you have a first timer, one or the other party will be unhappy afterwards. Either the selling party estimates too high, which leads to a serious price quote to compensate for the unknown, or, the selling party underestimates and looses money by doing the project (in some cases, it has lead to the bankrupt of companies). This is also applicable if you develop your software in-house… though expressed not in money but in time and time estimations, which is actually the same. It would not be bad for software development industry to go for a common project standard in approaching a unknown project where both recognise the fact that total time to come to completion is not certain. And yes, it might mean the project only is partially is done because “the money is gone”, but that is not uncommon in research situations. Pharmaceutical labs end research all the time because the proposed budget is burned. And then they take what they have so far. When you’re doing something the first time, then it is by definition, maybe only for your company, but nevertheless it is, and it can fail. That is the cost of innovation, and innovation never guarantees ROI…
Projects are typically smaller in size (or requirements) than products, and thus have short a typically smaller lead time. This allows developers to jump relatively fast to new development environments, tools and components. When finished and delivered, the teams go to the next project and have the option to review their environment and get the latest tools for the job. And when a certain methodologie, tool or component didn’t turn out to be as good as expected, the team can switch and use an alternative for the next project. This is a serious advantage for project development, because whatever environment you are using, the tools keep getting better and better.
Projects do not really come with a support period. Once the requested functionality is implemented, tested and signed off (and hopefully paid) it’s done. Of course, some bug might still occur later on, but, that’s never more than a few months after delivery because after that, all requirements have been used (and thus tested) by the end user.
That fact that they are smaller in size, and, require no real support afterwards, often allows developers to take shortcuts while building the solution. The technical debt that goes with this, is often not relevant as there is no successor to the project.
Another typical thing that happens in project development is that after a month, a year, or at least after the project has been signed off some time ago, new or extra requirements are formulated. Well, this is usually considered a new project, even though it is an extension. And you might worry about the fact that in the meantime development tools have changed, components have newer versions, and technical debt will cause some serious impact. Well, al of that will have happened, but, the time needed to move the old project to the new environment, adjust to the new component interfaces and rectify the rounded corners, will be added to the project lead time. Whether this is a good or a bad practice, is not a subject for this article.
Software product development
Product development isn’t about implementing one customer’s specific set of requirements. In product development, the set of requirements is defined by the product manager, which gathers these requirements by questioning existing customers, or by conducting market studies. His job is to get a list of requirements that are applicable for a large subset of customers. Most product development companies stop here and take this input to define their next “product release”.
I believe this to be a big mistake in product development and in this context I like to bring up a quote of Henry Ford: “If I would have asked my customers what they wanted, they would have asked for faster horses”. It is the task of the product development team (product manager, development manager, engineer, trainer, test engineer, …) to make sure the product is reviewed with respect to new technologies, and if needed, propose a innovative new product (release) that would be much better for the customer. Customers will never ask for this kind of change, because they don’t have this required knowledge, so they just ask for a faster horse.
This kind of product changes isn’t easy to pull off however, and is usually blocked by the management higher up the food chain. The reason has of course to do with money. In comparison to projects, where the effort is paid by that one customer, products are sold via licenses, and, it requires a reasonable amount of licenses to cover the expenses of development. Expenses that are already made, maybe months and years upfront because the large set of common requirements has a significant long lead time than projects. New architectures and innovation in product development is thus again an investment while the implementation of new customer requirements attracts extra customers and thus increases license sales.
This approach in software product development often leads to a software solutions that are a disaster from whatever side you look at it. Architecturally they are not up-to-date, or consist of different types of architectures glued together with a by some ugly work-arounds. Component wise they use three or four different versions of the same component. To install them you need four or five product specialists (aka consultants or experts) that must come over and install the product, only because experts can understand the complex configuration of the solution. Support is a nightmare, because each quarter of the product uses a different logging mechanism. I only name a few, usually it’s much worse.
I was and I am lucky to work for a company where management realised this and a release cycle consisted of three parts:
- 40% customer requirements, gathered by the product manager by collecting customer feedback and analysing the market
- 40% strategic features, which was the name for those requirements that came from the development, to change architecture, introduce new components and techniques. These are features that are needed to make sure the product can grow and is prepared for future extensions, stays manageable and competitive. You could call customer requirements “short term” thinking, and then strategic features are “long term”
- 20% paid customer features: we allowed customers to pay for getting certain requirements in a certain release. The requirements are not customer specific, they are generic, but, they would not have made it in the product without this promotion
You can argue about the percentages, and you can argue whether the third is really needed (we don’t do it anymore now I think), but the other two are definitely a must have if you want to have a future proof product.
In the above paragraphs I already mentioned a few typical differences in product development compared to project development. A very important difference is time, and this in many different aspects of product development.
- Defining a product takes weeks or months. Gathering and filtering the requirements is an intensive job, which must then be turned into functional and technical specifications, which have to be reviewed by all stakeholder. A very time consuming process, but this is needed to identify how the new release will look like in terms of architecture, which components will be needed, whether they will be bought or made by the team, create a planning, find dependencies, … and that’s all before the first line of code has been written
- Products take months or years to develop and this means a serious investment for the company that gets bigger as time goes by. That is why a product is never really done. We like to build the next version based on the current version and we attempt to reuse as much as possible to reduce development time
- Products are installed at customers, for many months and years to come, and as such they require constant support, many years after the release of a specific version
And it took me a while to get here, but this is where I would like to come to the statement I made in my introduction, and which was my reason for writing this essay. Most of todays methodologies and tooling focus on project development and not on the specific situation of product development.
Let me illustrate this with a few examples and let us start with the agile development that is common today, usually in combination with SCRUM. We iterate quickly to get customer feedback soon in the development process. In product development, we cannot go back to the customer because this job has been done in the beginning. Furthermore, a product is generic and it might require significant configuration to get it to work as the customer desires. The customer only gets a new release after a year, and isn’t consulted every week to see whether he likes the solution so far. Very often it isn’t possible to implement feature by feature either because a certain set of base components might be needed first, which could take weeks to get done. In such a scenario, a daily standup meeting also makes very little sense, since the engineers assigned to create such basic components need days or weeks to complete them. Think about a new communication layer for example, or a piece of database design. So agile as we know it today isn’t directly applicable to product development, but that doesn’t mean its complete useless either. The idea of iterating fast and gathering feedback soon is beneficiary in all cases. In my team I encourage engineers to implement what I call a “proof of concept”, which isn’t meant for the customer, but for the team, and it allows us to validate certain components and architectures very soon in the release cycle (that takes up to more than a year often). So we manage to get some concepts validated already in the first week of development. In product development, this is actually a fast iteration. It requires a good insight however in what must be made first, and the requirements that are essential to make sure the test is in any way valid. I haven’t found any methodology that corresponds with how I work every day. The traditional project management techniques (Prince, CMMI, …) have also good aspects which you should apply, but, are far to heavy for the limited set of engineers I have And it is clear that SCRUM “to the letter” is also not an option, and thus I end up with a combination of all of them. This doesn’t bother me that much since we have practiced it for many years with success. The only time when it gets a little odd is when people start asking wether you do agile development, which usually means scrum, and when you actually should say no but you end up saying yes anyway because the answers is actually this essay.
To get to this agile product development also requires some personnel management skills because product engineers often prefer working breadth than in depth. Yes there is a difference between product and project software engineers. Having recruited both of them, and having worked with both of them, I’m convinced there is a difference and it boils down to: a project engineer has a short attention span and likes new toys, a product engineer is more theoretical, cares less about the tools and whether something is hot. Project engineers are bored after a couple of months working on the same thing, while product engineers love to know every little thing that is going on. A project engineer will cut corners to create a solution, because the nature of a project will either make sure he is never hassled with the consequence of it, or enables him to rectify this later on. A product engineer will work generic and will constantly worry about creating technical debt in the product, because he realises that it will come back to haunt him in his dreams (sometimes literally). Again, I’m not labelling anything good and bad, just pointing out the differences you need to be aware of when you are in the one or the other scenario. God forbid you hire a product engineer for a project… only then you’ll experience what delivering late is (though it will be a solid project). God forbid you hire a project engineer that fills your product with short cuts and then moves on to the next company (which will happen as he is bored of product development after some months). Unfortunately it happens all the time.
Another buzzword at the time or writing (because that’s the nature of buzzwords, at the time of reading they might no longer be buzzing) is DevOps. Third time: nothing wrong with DevOps, it has some pretty good ideas, but in the context of product development it’s just not going to happen. If you are an internal project software team, you definitely should go for it because it is a great concept and all to often things fail because development and IT operations don’t cooperate sufficient. But when you develop a product , you do not know the customer yet, let alone his IT infrastructure. And if your product is sold via different channels, you might never ever know the customer. So people can talk about DevOps all day long, neither the concept nor the tooling helps product development. The only thing DevOps might achieve in product development, is make product developers aware that somebody sometime will have to install and upgrade and patch their product, and, it is worth investing time in it. In our company, we were aware of this already long before DevOps became a buzzword, and our product is still significantly easier to install than any of our competitors.
In this context, also Continuous Delivery often comes to play. Fourth time: good principle, but, in product development you will not continuously deliver.
Now you might argue with a lot of this and claim that even in product development, agility with his fast releases of product requirements shipping to the customer has huge benefits because the customer will profit from your incrementing feature set while at the same time you get feedback on the delivered goods. I thought the same actually until I experienced it myself with the product I’m responsible for, which is an anekdote I would like to share to illustrate point of view.
Early 2008 we released a new version of our product. It was a major review, and, in terms of “strategic features” I believe more than 70%. That is significant, but, at the time deemed necessary to stay competitive and to guarantee or product could grow in the future and expand to new markets. Hence, the company was willing to make the investment and survive a couple of years with the license revenue of whatever the software was at that time. The new architecture was clean, cut into different modules, and we had figured out a complete implementation and installation process from development up to QA up to the end customers. We could literally built in a feature in two days, make a setup package for the module with one click of a button in Visual Studio, provide it to the QA team, and after approval put it on a custom deployment server. From there on, the customer could get this update for this one specific module and immediately install it in his environment. It was impressive, and sales loved it. They could now sell licenses to customers and gather requirements and they would come in the product one by one on short term. Everybody would have the latest version of our product and share every latest feature. The overhead for the development team was low because it was automated, so they didn’t mind either. And then came the day when we ended up with some serious customers. Large enterprises, where hundreds and thousands of users use the product on daily basis to make the enterprise generate revenue. And they didn’t want all of this agility. From the IT operations point of view they have very strict timings on when software can be upgraded or patched. And updates and patches must go through a process of UAT, which requires the business to validate the changes, and this is a process that takes a lot of time so it’s only done once or twice a year. Furthermore, from the business point of view, they didn’t want all these new features. Not that they weren’t good features or they were buggy. No, the customers didn’t want them because it is a change in comparison to what they have, and changing the software meant that people had to be trained again, and training a thousand people for a new GUI costs a lot of time (thus money), and this for features the didn’t ask. Just to point that being agile isn’t always the holy grail of development in all cases, especially in product development. We didn’t throw everything away that day either of course, and we still use most of this infrastructure and design today, but, only to deliver the maintenance releases and patches, where being agile (aka fast or quick) is still an advantage. But when it boils down to features, we have a separate branch to work on that will become a next release, and we won’t bother the customer with that.
Enough on the process and have a few words on the tooling. Package managers are hot today and are the first thing that come to mind. Package managers are easy and there is nothing better than opening a new solution and add some of the nicest components with a simple command line statement. If another engineer opens my solution in Visual Studio, the NuGet components are downloaded right away in a blink of the eye. Or, for the NodeJS guys it’s a matter of sharing package.json and call NPM install on the command line. I like it a lot, all of them… but guess what? Not for product development. Not because the packages are bad, by far not. Never ever was there such a wealth of components that are of good quality and are free to use. But as I said, time is an important aspect in the difference between project and product, and, these packages tend to release very often, and often with changing interfaces. For projects this isn’t an issue, since this can be calculated in the extension of the project. For a product this can be annoying, because by the time the release ends, the components have several new versions available compared to when you started, and thus a changing interface might break your code near release time. No problem I hear you say, you can “fix” the version you use, so you don’t always get the latest version but everybody gets always the same version. True again, but that doesn’t take into account that one day your specific version of a package might no longer be available via the package manager’s repository, so what happens then? You’ll be forced to upgrade at that time, and that time might be a very bad moment, for example when you are quickly fixing a small bug, and this suddenly end up integrating a new version of this package with a total different interface. Additionally, you can fix version in a project or even in a solution, but, in product development we use many different projects and solutions for all the components and modules. There is no way to assure that all of these solutions fixed the same version. So we use package manager but adjusted the process in such a way that packages are first fetched to our own servers (and stored in source control) and only from there on can be used in the different solutions. That way, we know that when a bug arrives in two years from now, we are guaranteed to have the exact same component. It’s by far not that easy as running the package manager for your solution in Visual Studio, but it is in my opinion the best way to approach this for the future.
Another aspect is software packaging. How do you get your product to the customer. From the previous discussion, I think it is clear that all the “publish to web server or database” features that come with most development tools are not really useful in the context of product development. At best, the engineers can use them to test on their own servers, but that’s the limit of it. There are solutions such as InstallShield, but this is a very expensive solution, and not only for his licenses, even more for the number of engineers and time that are needed to get to a setup package. And this is money wasted, because at the end of the day, the setup package doesn’t add any value to the business using your software, they get the same feature set. To be completely honest: making large monolithic setups were nice in the days when we shipped DVDs to customers. But, more importantly, creating a setup.exe is by far not all there is to it. Today, all software is distributed over the net, and if you have a mature and reasonably sized product, it is in all parties’ interest that you only send over those bits the customer actually deployed. So it better be modular, and offered via deployment server, and have tools to manager the software on the customer’s machines. In the paragraph on agility I explained we created a separate process for this, and, for those who are interested, this is a combination of an ASP.NET web service, some custom made command line tools and Inno setup packages. I would advise Inno setup over InstallShield to any one any time of the year.
Coming close to the end in the chapter on product development, I suddenly remember I still have to add something about time estimation. When I talked about agile in project management I also mentioned the failing time estimations when it is the first time you do something. In product development we notice that product release are also often released late, or with less features in it than originally foreseen. So do we suffer the same problem as with project development? It’s a combination with product development. There is usually a part of the work that can be estimated quite accurately because it has been done before in the team. But if all goes well and you have strategic features, you know you are going to do some new stuff and thus you will get timing wrong, and, the more of the new things you’ll do, the further off you will go. As you know by know, I accept this as a fact of life in software development (or in any research type of activity). Time is in our advantage here, because when you have a reasonable series of requirements, a number of them will require more time than expected, but, some of them will cost less time so there is a certain part of compensation in the system. The fact that the set of requirements isn’t a demand from one customer but a general set of requirements, allows the product manager to skip a number of them to keep everything on track. So there is a little bit more flexibility here to mitigate the problem of time estimation, but it remains very hard and also for product development, there isn’t really a good process to deal with this.
A conclusion
There are most likely still a couple of other differences between product and project development that you might think off, but I have to wrap up and would already like to make a conclusion. As you can see, we use in product development a lot of things from project development, but, we always need to significantly modify them to fit them into our product development scenario and requirements. Actually, we must modify them soo much one might actually wonder whether it wouldn’t be better that we create separate methodologies for them, with specific tools or specific features in the tools we use today? Is this available already? Then please let me know! Are you having the same experiences and do you see the same in your company? Why hasn’t this been done? Is it because it is simply not possible or is it because everybody has different requirements in this field and thus the best we can do is make all our own processes based on the tools for project development? Not sure whether I will ever get an answer, but I’ll keep my eyes open for anything that happens in this area.
And what about cloud development?
Cloud development, by which I mean development of a cloud platform is indeed another topic, or maybe not. First let me clarify what I mean with a cloud platform. A cloud platform is a software solution deployed in the cloud and offers a service to different customers. I do not consider a customer’s website installed on Azure a cloud platform. Nor is the product installed for a customer on an Amazon VM a cloud platform. I guess you get the point.
Fact is: a cloud solution is made and deployed only once, just like a project. On the other hand, a cloud solution targets different customers, thus implements the requirements common to all of them, and one customer definitely doesn’t pay for the whole development. So a cloud platform seems like a combination of a project and product.
In my experience, most cloud platforms move from a project approach to a product approach as the platform grows. They all start very agile to get some traction in the market. In that startup phase, it is actually a project with the only difference you make it multi tenant. So they release often small updates to the platform so that the customers see the progress of the platform and believe in it’s future, while at the same time paying a small amount of money for it, keeping the business alive.
But when the platform reaches a certain size (in terms of customers and requirements implemented), every change done impacts more and more people, and more and more businesses, and thus the platform ends up in a kind of product scenario. At that point, they have to be very careful what changes they offer to which customer. Unlike a product however that can be updated with a specific version at one customer and not at another, there is only one platform deployed and thus it’s the same software for all customers. Usually this problem is mitigated by making these new features configurable, and, by default disable them for all customers. Customers that wish to use them can enable them, being aware of the consequences for their business. Customers that are happy with the solution as-is and do not need the extra features do not have to do anything.
The problem here is that this solution only works for customer requirements, and doesn’t help for any strategic features (as we called them before). Fundamental changes in architecture and design are typically a lot harder in a cloud platform, and therefore very uncommon. Luckily, most cloud platforms are very young and can still focus customer requirements and don’t need to worry about architectural changes or new techniques that are developed, but at some point in there lifetime they will reach that point. This will impact there business a lot, and usually means that they will build a second version of the platform based on the same data, and when you opt in to go to the new version, you are actually migrated to the new platform, rather than reconfigured on the existing system. Of course, if you have thousands of users (or maybe even millions), this for sure is not an easy task. One platform that pops into my mind here is Salesforce.com,which has actually reached the phase where they have to make significant architectural changes to stay competitive and up-to-date (for those who know Salesforce, I’m referring to their Lightning interface which adheres to “responsive” principles, while there old interface didn’t support this because it was build long before responsive became the standard).
Working on a startup cloud solution myself (in the little spare time that I have left), I can experience the methodologies and toolset available for project development when programming the pieces of our offer.And this works quite well. However, knowing what I know from my experiences with products and what I have seen in other platforms, I realise that one day pressing the “Publish” button won’t be possible anymore, and we will have built our own process by than, like many others are did before, and will do after us.

The beauty of HarpJS and harp.io to easily serve a static website
Update: though the below it still valid, it seems harp.io is starting to end their services and they closed my subscription already. This doesn’t affect the HarpJS server of course, though, this means you’ll need another platform where you can install NodeJS and extend it with Harp in order to get your site running.
Sometimes, when you are asked to build a website, you get the following set of requirements:
- They need a reasonable amount of pages, not a one-pager or the home/about/contact website, but more up to 10, 20 or 30 different pages
- Different pages means they really want every page a little different in layout and text, pictures,… so no page is equal to the other
- Some elements are however recurring in every page, e.g. footer and header, and some elements are recurring in half of the pages, e.g. a side bar, which you do not show in every page but only when there is some room left to fill
- The content and pages will seldomly change, and if so, they will contact you to do it
- There are one or two very specific requests you will have to implement in some pieces of client side javascaript, and you know that in the future the customer can ask any question to change a certain page in a certain way (that might not even make sense to you)
Since I’ve had this kind of request a couple of times, I’ve spent a reasonable amount on thinking and experimenting how this is best handled. I considered a series of options:
- just HTML, CSS and Javascript: Though this is doable, any reasonable developer will soon encounter the moral and enthical problem that he is sometimes copying and pasting code, which are bad practices. Since you will be the one who has to handle the changes every two months, it will be you who will forget where he copied what and thus get an inconsistent update. There is something as JQuery widgets, but this is more for “repeating” particular parts on a single page. And even though the templates can be separated from the page, it is still not a beautiful solution to insert a part of javascript to attach the widget on a particular location. Plus, you can see the page parts being loaded after the page as loaded.
- a CMS system: CMS systems are good if you have the same type of content that must be published regularly by many different people. For example, the same type of articles on a blog, the same type of objects you sell in an online shop. Usually the layout is then determined by some sort of theme that defines how each of these objects must be rendered. In my situation, where every page is different, in style and content, it would mean that I have a content type for each page, and, must make a theme page for each content type, of which I will have only item. Apart from the setup of the CMS, this means I still have to make something per page, which seems a bit too much work.
- Website builders, Squarespace, Webix: Though these services really make it easy to build a responsive website, and I tried most of them, I always run in trouble. Either, their templates cannot be adjusted enough, or the editors do not give you enough freedom to put the last pixel on the right spot. Custom javascripts are also not always that easy to add, and if the customer makes a request for a little change, you’ll have to see whether the tool allows it, not whether it is technically possible. It’s frustrating and hard to explain you cannot do something your customer has seen on another webpage… it affects your credibility (did you choose the wrong platform, or ar you incapable, because the others can).
- Custom server side code: Use of an MVC framework such as ASP.NET MVC, or SailsJS for this seemed like a reasonable overkill to me. It costs reasonable amount of time for something that you as a developer can use to achieve this, but will cost time and money, and doesn’t add any value to the customer.
- Client MVC framework: I’m a big fan of AngularJS, but, for this kind of requests, it is a little over the top. Setting up routers, controllers and directives is a little more than I want to do for such a simple task.
So at a certain point in my research I ran into harpjs, “the static web server with built-in preprocessing“, which sounded nice and turned out to be a perfect solution for my problem. Actually, I think they made it because they had the exact same problem. A simple solution for a simple problem. HarpJS is based on NodeJS, though when you are using it, you don’t notice this. But it’s good to know it runs on NodeJS, at least you are sure it is based on a proper engine. HarpJS gives you that HTML web server with an extra twitch on top of it.
The advantages of HarpJS are:
- You can use partials, so you can split of certain portions of your HTML code in separate files and then insert them very easily in the other pages using simple tags. The Harp server will make sure they are inserted and all is sent to the client as one HTML page. The client doesn’t see where the different parts come from and the page is renderd as one.
- You can use SASS or LESS, which is really good to avoid the complex CSS pages you anyway always end up with, and, you don’t have to do the SASS or LESS building yourself
- You can run the harp server locally and test your solution
- I started with a responsive template and theme I bought online for 5$, which I split up in partials. Now I have nice responsive pages but I’m still in full control of every pixel in the website. Buying such a template is almost always profitable these days, because starting a layout from scratch will most likely cost you more than 5 or 10$. You can still change the parts you are not 100% happy about if that would be really needed, but in all other cases, it saves you hours of time. Also, if you are more a developer than a designer, you are not good at design anyway.
- I can add, remove or modify any line of client code or framework that I want.
- There are some other fun tools and scripting languages you can use an that will get automatically processed, such as Markdown and Coffeescript, but I don’t use them.
This way, I was able to create the initial website pages in a matter of hours, and it will cost me in total two or three days to put everything in the correct place, without writing a single line of server side code. I used SASS for the extra styles I needed, but I don’t have to do the preprocessing manually. I can just focus on writing the code and content that is specific for this customer.
The thing is of course that by using HarpJS, you are actually also using NodeJS, and, consequentually, you need a NodeJS hosting to serve your website to the public. So our simple static website suddenly requires something different than a simple HTML hosting you can find for free or for 1$ a month. That is where harp.io comes into play, the hosted HarpJS server, that comes with a nice extra: publishing from your Dropbox account. Apart from having a fair price for hosting, publishing from Dropbox makes it really easy to build and maintain this site. Just do everything locally and test with your local HarpJS server that works on your Dropbox folder, and when done, browse to the Harp.io website and publish with one click.
As a developer, I know we like to have complex challenges and build websites with reasonable server and client side code. But sometimes the customer needs simple things, and then HarpJS is really a nice solution.
How to think about databases
Very interesting read… and complies with my own experiences
As a maintainer of PouchDB, I get a lot of questions from developers about how best to work with databases. Since PouchDB is a JavaScript library, and one with fairly approachable documentation (if I do say so myself), many of these folks tend toward the more beginner-ish side of the spectrum. However, even with experienced developers, I find that many of them don’t have a clear picture of how a database should fit into their overall app structure.
The goal of this article is to lay out my perspective on the proper place for a database within your app code. My focus will be on the frontend ? e.g. SQLite in an Android app, CoreData in an iOS app, or IndexedDB in a webapp ? but the discussion could apply equally well to a server-side app using MongoDB, MySQL, etc.
What is a database, anyway?
I have a friend…
View original post 3,445 more words
Custom bootstrapping an AngularJS application to load configuration settings
Why do we need custom bootstrapping
If you use AngularJS for a larger application, you sometimes need information before AngularJS itself is started (often called boostrapped). In my scenario, my front-end AngularJS application connects to an API on another server, and there are different servers for different purposes (development, QA, …). To which server I must connect is in a JSON file in the root directory of my front-end application. This way I can use $http to get this “local” file, read the API base URL and then call the API functions. Why this is very handy is not the topic of this article, but it helps to move code and to address different servers solely by chaning one little file and does not require any code changes.
My application however stores if the user was logged in last time. If so, it will immediatly fetch a number of values from the API using a locally stored user authentication token. This is done using an AngularJS service.
Due to the async nature of $http you now have a “race condition”.
The reason is simple: the call to the local $http configuration file can or cannot be completed while the AngularJS application started to initialize the user service, which will fetch the initial user values from the API. If the configuration file is loaded, the call to the API will succeed, but else the API URL is not configured, thus it will fail.
A simple but bad solution would be to first get the configuration file and only upon completion of that call initialize the user service. It will work, but you created a situation that will bite you in the … later on:
- If you have other services with other API calls, they will also have to follow the same pattern and wait until the first get of the configuration is done
- Other code cannot execute as long as the services are not intialized, or at least has no sense to execute, so you will have to “wait”
Custom bootstrapping an AngularJS application
If everything has to wait until the configuration is loaded, you can just as well wait with bootstrapping AngularJS. The major advantage here is that your AngularJS application is not aware of this first required step and can be developed as if the URL is always availble.
The first step in bootstrapping AngularJS yourself is removing your ng-app attribute you have in your HTML file. It is this attribute that will bootstrap AngularJS and if you don’t remove it, your custom bootstrap will fail and return you an error “you cannot bootstrap the same application twice”.
The second step is loading this configuration file and bootstrapping AngularJS. As such we need to execute a small piece of Javascript code that will be executed as soon as the document is loaded. Even though your AngularJS application is not yet bootstrapped, we can already use the angular libraries to attach some code to the document ready event, and load the configuration using $http. Once that is done, we launch or application.
angular.element(document).ready(
function ($http) {
$http.get('api_config.json')
.success(function (data, status, headers, config) {
angular.module('myApp').constant('StartupConfig', data);
angular.bootstrap(document, ['myApp']);
})
.error(function (data, status, headers, config) {
var default_config = { api_url: 'http://localhost:1234/api/' };
angular.module('myApp').constant('StartupConfig', default_config);
angular.bootstrap(document, ['myApp']);
});
}
);
I usually put this code next to where I define my AngularJS application and where I put all the other application configuration. After fetching the URL, we will make it available via an AngularJS constant that can then be injected in any service or controller that needs it. After all that is done, the AngularJS application can just start.
If you have more initialisation to do, it might be better to introduce extra functions and work with promises to keep things clean, but in my case this is sufficient. Note that when there is no file found, I implemented it in such a way the application would still start but connect to some default URL. Also this behaviour depends on your requirements.
Installing, configuring & provisioning a Skype for Business trusted application server
Two weeks ago I encountered something strange: when looking for an article on how to install a Skype for Business (SfB) trusted application server, I couldn’t find a step-by-step instruction.
It could be because I’m a terrible Google or Bing user, or because there really isn’t one explaining what I wanted to do. All I could find were simple instructions on how to configure a trusted application pool in SfB, using the administration pages or using powershell commands, and even though that is a required step, that is only part of the story: you do need an actual application server. MSDN itself also hasn’t got a step-by-step on doing this, so I decided I write one myself based on all the info I could find all over the forums, KB’s, codeproject, MSDN, stack overflow, Lync articles,…
So what did I want? I want to develop UCMA 5 trusted server applications, using application endpoints, not using user endpoints. Those who have knowledge on Microsoft Lync or SfB (which is a requirement for this article I’m afraid) know that if you want to run and/or develop this, your application must run on a trusted application server. Additionally, I want to use auto-provisioning of my trusted application. There are a lot of manuals (on Lync at least) describing how you can get a none-domain development machine with Visual Studio to work and connect to your Lync server by providing all endpoint info, doing crazy things with certificates and so on, but this is not what I had in mind. Even more because a lot of those methods are trial and error by many different people. I wanted my trusted application server to run in the SfB domain (a separate test domain for development), completely equiped to run trusted applications, and containing a Visual Studio installation to test/develop a UCMA application.
First step is to think about how our domain will look like. For Lync, we need at least a domain controller and an Exchange server to work comfortably, so I took a router and five machines to create a separate network that implements the Matrix.vox domain (not really original, but the thing needs a name):
- DC1: Windows 2012 R2 Standard, domain controller installed (and thus DNS) and certification authority. Make sure to install this CA role, and, make sure to write down the name of the CA, since you’ll need this later on when configuring your trusted application server. I created five domain users that I will use to sign in to SfB. Instructions on how to install a domain controller are very easy to find, and are not part of this article.
- EX1: Windows 2012 R2 Standard with Exchange Server 2013. Installation of Exchange server isn’t hard because there is a lot of documentation available (it is a couple of years old in the meantime). Also, take into account that I’m not trying to build a mail infrastructure here: Exchange is only installed because certain functions of SfB rely on it. For example, I did not configure it to send mails to the outside world, but sharing contacts and agenda’s is possible.
- SFB1: this machine is my SfB server. I use a simple installation (no high availability, just a single server installation). A magnificent step-by-step manual on how to install this can be found here. The rest of this article assumes you have working SfB installation where domain users can sign in, and where you have access to the administration interface, powershell and topology builder! Of course, this post assumes you have basic knowledge of SfB and UCMA SDK.
- APP1: this server will be our trusted application server. It is a clean Windows 2012 R2 Standard edition, and I added it to the domain.
Important note: Since my installation is a separate domain for development and testing, I have a domain administrator account available at all times to do these actions. If you do not have this, for whatever reason, take into account that certain actions require certain privileges. See the MSDN reference on the commands to find out which priveleges you need.
Creating a trusted application server in SfB
First step to do is create a trusted application server in the SfB environment. This can be done either with the Topology Builder, or with powershell commands, whatever you prefer. I prefer the Topology Builder. Open the Topology Builder, browse to the “Skype for Business Server 2015” node of your organisation and right click the “Trusted application servers” folder to add a new server. If you start with a clean installation as I did, this will be fairly simple. If you are in complex environment, or an upgraded system, make sure to pick the right node in the right organisation.

Right-clicking the node will provide you with one option called “New Trusted Application Pool…” and thruth to be told, I think this is a strange name for the option: one would expect “New trusted application server…”; after all, we are in the trusted application servers node. As it turns out, “pool” and “server” are not really used consistently in the SfB software. I guess a server holds a pool of applications, but even then naming could be better. Either way, a wizard will popup, asking you the FQDN for your new trusted applications pool. This should be the FQDN of your application server.

Click Next and associate the next hop server (or pool). In a simple installation, you will have only one option.
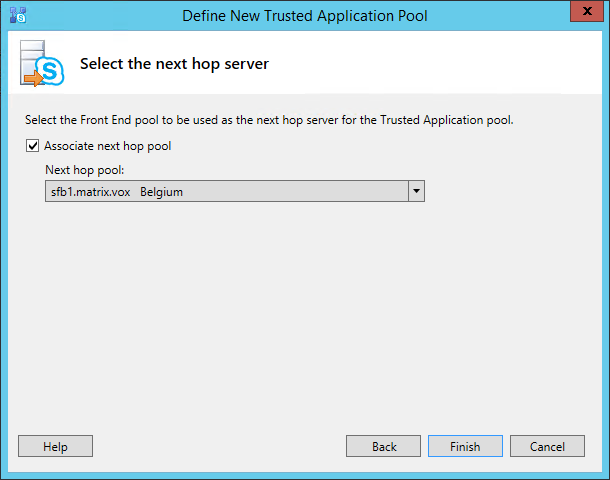
Click Finish to end the wizard. Even though your server will be part of the topology, the topology must still be published. To publish your topology, right click the root “Skype for Business server” node and select “Publish Topology…” menu item. A new window will popup. Just click Next.

The topology should publish without any problems. Don’t worry about the to-do list it presents. It basically tells you that there are some things you have to do on the application server, which of course are the next steps in this article.

Before moving our focus to our application server, you might want to check the SfB administration website. Your new application pool should be visible already. Since we didn’t do anything on the server yet, the replication flag is still red. We’ll fix that shortly. Also, there are scenario’s where you don’t really need this replication, but if you are going for auto-provisioning of your applications, this is a must have.

On the application server, there are three things to do, assuming the server is already in the domain (if not, do this first):
- Install the SfB core components, and set up replication of the configuration store
- Add the necessary certificates
- Add the UCMA 5.0 SDK
To set up the core components and replication, insert the SfB installation media in your application server, and run the deployment wizard. In the deployment wizard window, the prepare active directory step should be checked as completed. If this is not set, you are most likely not part of the domain, or, you are not able to access the domain or domain information. Click the “Install or Update Skype for Business Server System” link.

In the window that pops up, select the “Install Local Configuration Store”. This will install the core components and the local configuration store.

In the local configuration store setup window, select the option to copy the information directly from the central management store and click Next button. Click the Finish button in the window that comes after it.

Once the setup completes succesfully, the deployment wizard should show local configuration store was installed succesfully.

After completing the core, I found out two steps are needed to complete the replication of the configuration store. Not sure whether this is the official way, but, it is the way I got it working twice, and I found no other way to get it working. First step is to execute the Enable-CsReplica command in the SfB powershell window. This apparently doesn’t seem to do very much… it just enabling, not replicating I guess.

If you run the Get-CsManagementStoreReplicationStatus cmdlet, you will also see our local store is not yet up-to-date.

Most of the articles I read apply powershell commands to invoke the replication at this point. However, in the installations I did, that didn’t do the trick (or at least, made the replication work). It turns out a reboot of the system is the magic action to do here. As such, step two to complete the replication is a reboot of your system. When your application server is back online, go to the SfB administration website. If all went well, you should see your application server is up and running and replicated!

This completes the first of three parts: installation of the core components and replication of the configuration store. Next step is adding the required certificates to your application server. Remember that in the beginning of the article I told you you will need the name of the CA of your domain…. well this is the time to get it. Fire up the SfB Powershell window and execute the Request-CsCertificate command. The command takes the following parameters:
- New: just indicating you want a new certificate.
- Type: default.
- CA: the name of your CA, formatted as FQDN\CA-name, so in my case this was dc1.matrix.vox\matrix-DC1-CA. Just providing the name will not work.
- Verbose: though the command will work without verbose option, the verbose option shows you the certificate details, especially the thumbprint is interesting, which you will need in the next step. If you don’t use verbose, you’ll have to get the certificate’s thumbprint in another way, but why make life hard if it can be simple as setting the verbose option.
Select and copy the thumbprint once the command is completed.

Second command to execute is the Set-CsCertificate command. This takes the Type and Thumbprint parameters. Make suure to use the same as above, and things should work out fine.

That’s all for step 2. Step 3 is the installation of the UCMA SDK.
Important: some posts and articles on the internet suggest that the only thing needed on a trusted application server is the UCMA SDK. After installing the SDK, one needs to run the “Bootstrapper” command manually to install and enable the replication.
In my installation(s), this never completed succesfully, even though I had clean machines. Even more, when you want to install the core and configuration replication via the SfB setup (as we did in our first step), you will encounter an error saying the core components are already installed! Don’t panic when you encounter this error. Go to add/remove programs configuration panel and remove SfB core components. After that, run the SfB setup again and install as we did, then install the certificates. As the UCMA SDK is already installed, the next steps of our article are no longer needed, and you are ready to add applications.
Download the latest UCMA 5 SDK from the MS website and launch it. There is only the Install button, so just click on that one. Your installation might fail with the below error: you need to install Media Foundation feature on your server. On a Windows 2012 R2 Standard machine, this is not installed by default. As such, close the UCMA setup window, go to your server administration overview, find the add roles and features panel, and select the media foundation feature. Once that is installed, run the UCMA setup again and it should finish without any errors.

And that’s all there is to make a trusted application server ready.
Adding a trusted application
Once you have this server available, you can add one or more trusted applications to the server (or pool, as you wish). For completeness, I add the steps required to create a new trusted application and endpoint in the SfB installation.
First, execute the New-CsTrustedApplication command in the SfB powershell (note: you can do this on either the application server or the SfB server). The command takes following parameters:
- ApplicationId: a unique name for your application. Strictly spoken, this name doesn’t have to be unique, it has to be unique in combination with the FQDN of the server. That is why in all following commands, you will have to provide the FQDN as well. Of course, to avoid confusion, choosing a meaningfull and unique name is the best thing to do and never hurt anyone.
- TrustedApplicationPoolFqdn: the FQDN of the application pool where the application will run on.
- Port: a port number that will be used.

After completion, you’ll see all the details of your trusted application. Though this might be sufficient for your purposes, most applications do require an endpoint (depends on the type of application you are writing and what it is supposed to do in SfB). To add an endpoint to your application (and you can add more than one if this would be a requirement), execute the New-CsTrustedApplicationEndPoint command and use the following parameters:
- ApplicationId: the name you provided for your application.
- TrustedApplicationPoolFqdn: the FQDN of your application server.
- DisplayName: a free to choose display name for your endpoint, which will show up if your SfB users connect to the endpoint.
- SipAddress: the SIP address of your endpoint. Of course, check with the sysadmin whether the name is ok to use (or not yet in use by other people or applications). Make sure you provide the addres with the sip: prefix, else, the command will fail.

When the command completes, you have a new trusted application defined. However, it still requires to be “activated”. Run the Enable-CsTopology command to make your changes active in the SfB environment.

Now you can go to the SfB administration website and see your application in the list of trusted applications.

Verifying the installation
To verify our installation was succesfull, and to check whether the auto-provisioning works for our newly declared trusted applciation, and since this is a development environment, I installed Visual Studio 2015 Community Edition on my server. Create a new C# console application and add a reference to the Microsoft.Rtc.Collaboration assembly that is in the UCMA installation directory.

I used the following code to check everything was working.
Important: this is bad code, and uses bad practices. DO NOT USE THIS IN ANY WAY for real applications. It is only intended to verify our installation and configuration!

Note that we can use the ProvisionedApplicationPlatformSettings here, and the only thing that must be provided is our application ID we configured before. The application ID must be formatted as “urn:application:applicationID”. The first parameter is optional. The ApplicationEndpointSettingsDiscovered callback function will be called only if you have an endpoint configured for your application. There is some logic in the world after all. Run the application and check whether any exceptions occur.
Important: when you run this application the first time, you might get an exception that the SIPEPS assembly was not found. This exception occurs because by default, Visual Studio will prefer 32 bit compilation, and, the server and SfB components are 64 bit. Go to the project settings and change the build options to make a 64 bit application, and all should just work fine.
Once you have the endpoint available, you can use the endpoint just as any other type of endpoint in SfB; same goes for the collaboration platform object. The biggest change compared to other applications, are these few lines and the ProvisionedApplicationPlatformSettings usage.
Conclusion
Next time somebody looks for a step-by-step manual to install a trusted application server, I hope they end up on this page, and find this a proper solution. I took me some time to figure it all out. MSDN documentation is usefull but only to explain the different commands involved, you won’t find the different steps nor the order in which to execute them .
As mentioned in the introduction, this is not the only way to develop UCMA trusted applications. There are ways to build up a development environment without your machine being part of the domain, and without provisioning.
Finally, it is obvious why most of the sample applications MSDN provides for UCMA applications, use user endpoints. For user endpoints, all the above is not needed and you can run your application simply by providing user credentials. In most cases this will be enough, and then you should use them. Only when you specifically need application endpoints and the power that comes with them, the above can help. In production, you will (almost) always run on an application server that is prepared as I did… it will never be a “development” machine. As such, even when you develop using another setup, it might be good to have the above setup to test how your application will behave in an environment similar to production.
Create REST based applications using SailsJS, Waterlock, AngularJS, Restangular and Material, An introduction
I’ve done reasonable research on different web stacks and combinations of stacks to find out what would be the most useful for me. I ended up using the SWARM stack, which, as far as I know, is a term nobody uses (yet), but is short for Sails + Waterlock + Angular + Restangular + Material. In all follow up articles I will show more code on the different topics, but below you can find the complete “why” I choose these technologies.
First of all, useful for me can be different than it is for somebody else, but here are my criteria for “useful”:
- As platform independent as possible, for both development and running the application in production.
- Front and back separated by a REST interface. You never know whether you will have to make another front-end one day (e.g. an app for iOS or Android), and REST keeps these options open
- Front and back should work with a well documented, easy to understand framework so I can add functionality very fast without worrying about the technical details, nor the implementation of too much GUI
- I don’t want to worry about the DB that is used… because I’m not sure on that part yet
- Open source, preferably MIT License or alike, and well supported by the community. I don’t want to end up with a component somebody wrote “half” or abandoned long time ago.
For the first item on the list, I’m convinced NodeJS is an ideal candidate for the back-end, since it avoids the need of a compiler, heave duty webserver and alike… it’s pretty straightforward, runs on Windows boxes, Macbook,… just have to share the files. Also, all reasonable cloud providers are able to run this, so we’re safe with this choice.
Continuing on the backend, writing a REST application from scratch in NodeJS is still a reasonable amount of work, and reinventing the wheel has helped no one ever, so a web stack that enables this would come in handy. I started with the Express stack, which is pretty basic but already nice to work with, it still required me to do a lot of work. I looked at Loopback framework, where there is a pretty Arc frontend, but this isn’t completely open source (as in free), and for one reason or another I couldn’t find my way in it, so I didn’t stick to it. After checking out a few alternatives (Koa, Hapi, …), I stumbled upon SailsJS, and I’m a fan ever since! Though SailsJS is actually an MVC framework, it creates a REST API by default for all the model/controllers, and you do not need to use the views at all, but can still profit from all the other goodies it offers: policies, nice structure, clear config files,… all very simple to learn. Equally great and a fantastic advantage is the use of the Waterline ORM, which doesn’t force you in the SQL or NoSQL corner, but supports both of them, and even combinations. In development, it works in local files, so you can postpone your choice if you’re not sure yet, but still develop. For a REST backend, I could not find any better solution that leaves me with so many options, and is so easy to learn.
Note: Waterline ORM can also be used outside of the SailsJS framework, and I would advise it in any way since it make DB development really easy and relieves developers from the actually database dependent stuff.
One item left for the back-end was user authentication, since SailsJS doesn’t provide this out-of-the-box (for good reasons). If your requirements are front and back-end separated by a REST interface to support other apps in the future, you must be consistent and the only way to go is web tokens. Cookies are not done (anymore, for authentication), and session authentication will bring you into trouble if you ever want to scale up, or work with apps that do not support this. SailsJS is based on express and all express modules are reusable, so by default people tend to move to Passport for this task. Truth be told, I’m not a fan of Passport… just couldn’t find my way in it (as you might have noticed, I rely on “feelings” for my selection of components, so this is pretty subjective I guess). As an alternative I found Waterlock, which is specifically designed for JWT authentication on Sails, and it does the job just fine!
So with the back-end covered, time to go to the front-end. I’m a fan of AngularJS since the day I met it, and if I see the community around it, I’m not the only one. It has a clean (MVC) structure that makes it really easy to make single page applications, and though “single page application” was not really one of my requirements, it makes life simpler. With AngularJS however, I have two issues:
- Absence of nice HTML controls. The nice controls are not provided, since it is no concern of an MVC framework, but, nobody wants the default HTML controls today
- Calling REST functions is not easy enough, even if there is something like ngResource available
On the HTML controls part, I started with bootstrap, and even though it is nice to work with, it sometimes doesn’t fit into the AngularJS modus operandi. There is an Angular Bootstrap component, but this wasn’t satisfying either. After that, I encountered Angular Material library:
The Angular Material project is an implementation of Material Design in Angular.js. This project provides a set of reusable, well-tested, and accessible UI components based on the Material Design system…. Material Design is a specification for a unified system of visual, motion, and interaction design that adapts across different devices and different screen sizes.
Nothing more to say on that one. Library works great and delivers nice controls. So only part left is call the REST API from within AngularJS. After looking at some generators and alike, I came across Restangular:
AngularJS service to handle Rest API Restful Resources properly and easily
Restangular really delivers what it promises, works nice in AngularJS and calls SailsJS API without any problems, has a good documentation and is well supported.
And with that all in place, I had my full stack ready that meets all my initial requirements for developing web applications. Note that an extra consequence is that all of the pieces in this architecture are written in Javascript, so there is only one language used. Though it isn’t an explicit requirement for me, it could be of interest for some development teams
Installing IISNode 0.2.2 on Windows 2012
There are a number of articles written on IISNode, but I didn’t really find an up-to-date article that describes how to install the latest version on a clean Windows 2012 using the setup packages provided by IISNode, so I’m just writing down the experience to save another developer’s time, because it wasn’t “all out of the box”.
First of all the basics:
- We use a Windows Server 2012 installation, 64 bit (of course), simple standard version (it is a test setup from my side)
- Make sure IIS is installed on this system, so that you have working web server… after all it’s called IISNode so there is the requirement for an IIS
- Make sure NodeJS is installed on your server. IISNode does not install node itself, it is only the glue between NodeJS and IIS (and that is a good thing!). It however does not check whether NodeJS is installed, compared to IIS where the requirement is checked.
ORDER IS IMPORTANT! I accidentally didn’t install all these prerequisites upfront (which is just a nice way of saying I forgot a part), and had a hard time to get IISNode working on the system. Also a read a bunch of articles on problems when only using x64 packages of NodeJS, so installed both x86 and x64 packages of NodeJS on my machine. Don’t know whether that is still a requirement, but it was at one point.
Installing IISNode
Installation of IISNode is getting a matter of downloading the package from the github repo. I used the iisnode-full-iis7-v0.2.2-x64.msi package, which was the most up-to-date at the time of writing. I just ran default installation, and this creates an installation directory in C:\program files\iisnode (I expected it to be in the Inetpub folder to be honest).
After installation go to the installation directory and run setupsamles.bat AS AN ADMINISTRATOR!
Running hello.js
Just as with any other technology, our first goal is getting the “Hello World!” running, which is a matter of getting hello.js to work. The hello.js is located in C:\Program Files\iisnode\www\helloworld. If you did everything correct up until now, you should be able to browse to http://localhost/node/index.htm that contains a link to helloworld example, which will show the readme file on the sample. Launch hello.js from there and you should see this:

Important: if you want to play with the installed samples in the directory they are installed, you will, with default permissions, not be able to change the files since you have no permissions to save files in the Program Files directory! Easiest way out is to change the security permissions on the www folder of the iisnode installation directory !
Running express applications
The samples directory contains a number of sample projects, amongst them one with Express framework, so if you need this, make sure to check those out because there a couple of specific items to be added to the web.config file regarding the URL rewrite module. On the topic, there is perfectly fine article here which makes it useless that I write about it. Important thing to achieve this, is the fact that this configuration is done in IIS web.config file, which is unknown to the node project itself and does not require any changes to your legacy code… which brings me to the next topic.
Transferring legacy NodeJS http server applications to iisnode
IISNode requires little or no changes to your application. The most obvious one is the location where you set the port number for your server to listen. Since this is determined by IIS, this will be passed as an environment variable to your application:
http.createServer(function (req, res) {
...
}).listen(process.env.PORT);
Second part most of us have in custom applications is some additional npm packages, e.g. I use Winston to do some logging output. Luckily, this doesn’t really change with IISNode: just run npm install –save command to add your package and all will be just fine…. so that is a relief and makes life easy and makes sure I do not have to alter my code too much.
Important: if you create your own applications in another location, make sure that NodeJS has proper access rights to the folder, else execution will fail since NodeJS process launched via IIS runs in lower priveleges than your own account. The error does not really mention this is the problem, but in the description there is a small remark on that a log file was not written, which made me come to this conclusion.
Dual run
Taking the above into account, these changes are that limited, that when you make sure to add a little line of code in your application (var http_port = process.env.PORT || config.http_port), you can still run the application from the command line using the node.exe executable as before, and that is a really good thing. It allows you to run the same code on servers where IIS is not an option, which is a enormous advantage!
Why I like a NodeJS web application on Azure using SQL as a backend
I’ve been doing a lot of studying lately on which technology is best for my new project, and with the abundance of frameworks life doesn’t get any easier. I have a number of requirements which most of us have when creating a new web applications:
– A framework that is easy to use and well supported (in terms of modules, libraries, … whatever makes us not invent the wheel twice)
– Must run in the cloud
– Must run for free in the cloud while I’m developing the thing. I only want to pay as soon as people pay me
– Must be able to develop code easy on any machine
After all my research, I think I found my ideal combination: it is a NodeJS application that delivers a REST API and accompanying AngularJS client pages in combination with SQL on the backend. A number of people reading this will put question marks with this choice of technology, but, there is a good reason why this combination makes sense.
Why NodeJS?
I like NodeJS for two reasons, which are not accidentally on my requirements list:
– It’s javascript, and doesn’t require a compile step while developing. Hence, it is easy to develop NodeJS applications on any system. Macbook, not a problem. Pc at home, with windows 8.1. No problem. Editors in abundance, see my previous article on Visual Studio Code fore example, but for Windows there is also Visual Studio Community edition, one of the better Javascript editors available today.
– There is an extensive list of free modules available via NPM, and up until today, I haven’t found one problem I couldn’t tackle with a module that is freely available. Is seems me from reinventing the wheel, just make up the glue to deliver a nice service
Note: I like C# code as well, don’t get me wrong, and I’ve written web applications in MVC as well. I just like the fact that NodeJS has no compiler requirement, which makes it very easy to develop.
Why Azure?
Most of the people I meet associate Azure development with ASP.NET websites (with our without MVC). That is one option, but NodeJS applications are equally good supported, and, web applications are for free on Azure! You can say about MS what you want, but Azure is a nice piece of work, and the fact you can easily run NodeJS applications on a free of charge web tier is fantastic. Deployment via Git is included and super easy, so what else do you need? I think most people don’t know these options, and often turn to Amazon and OpenShift for these kind of things, as they are more commonly associated with NodeJS.
Though not really applicable for a simple website, but, there is also an Azure module for NodeJS available to manage your Azure objects, so don’t underestimate what NodeJS and Azure have to offer.
Why SQL?
If you see NodeJS, you always see MongoDB or another NoSQL backend. I like MongoDB and NoSQL for what they are made, but, my data is simple and relational, so why should I go for a NoSQL DB? It would just end up in objects referring to each other like a relational schema, I would use Mongoose to enforce all the constraints…. so at the end of the day, SQL does the job here better than NoSQL. I don’t believe following a trend or hype is a good thing if it just for the sake of the trend. If you can get profit out of it, do it, else, stick to what you have and works.
NodeJS has no issue with SQL, for those who are in doubt. There is a great library called Sequelize (check npm repository) that makes it really easy to work with traditional SQL databases.
A limited MySQL DB is also available for free on Azure, so that’s good for kicking off my development. When the app grows, it might not be sufficient anymore, but the customers should pay for the growing storage cost, so no worries about that.
Note: it thought it was possible to get a limited free MS SQL instance for development, but, this seems not to be available anymore. However, the Sequelize component should hide most of the backend for us thus this should be doable.
Note: it is possible to get a MongoDB instance as well on Azure, thought I’m not sure whether that is for free to start with (up until a number of MB’s). If you would need a MongoDB in the cloud, you can always turn to MongoLabs for a free MongoDB instance in the cloud (to start with). I takes only 5 minutes to register and have it working.
Conclusion
For these reasons, this combination is my ideal environment. It might be yours as well for the same or even slightly other reasons. It’s not a trendy combination, but I believe it is a solid one, and that is what counts at the end of the day.

Intellectual masturbation in software development
This week I attended the Techorama developer event in Belgium, with an opening keynote of Hadi Hariri titled “chasing the silver bullet”. To summarize the keynote: “new” technologies arrive every day, and marketing tries to convince us (developers) we always have to use the latest and shiniest new tools available on the market. This is not true, and people with some years of experience in the development community know this: you should only use the latest and new tools when it adds value to whatever your business is, not for the sake of using new things.
This made the keynote relevant to me in two ways:
First of all, those events are always filled with “young ones”; developers with zero to five year experience who actually think they are going to change the world. They won’t, maybe one, if lucky. I was one of those young ones ten years ago, and when I attended these kind of events, I equally felt the urge to go back to the office and introduce all these nice new things. It is easy to get brainwashed when you are young. And there is the exposition room filled with sponsors that all claim to use and play with these latest things, so you kind of feel alien if you would think different. Of course, those companies are in general in the IT consulting business, so they only profit by introducing new technologies and sell additional services to use it, and if you are part of such a company, you might be able to actually always use the latest releases. To ISV companies who develop products, using the latest is only relevant if it adds value to your product, because it will come back and bite you.
Second thought. The word that came immediately in my mind, was the term intellectual masturbation. Mr. Hariri did not use it during his talk, but it would have perfectly fitted the topic at hand: Intellectual masturbation simply means the engineer does something because it is a challenge for his brain to apply a new technology, and he will get satisfaction from it, but does not take into account whether this adds any value to the product or company that is actually paying him. Where I work, a company creating software for almost twenty years, we use this term every time an engineer comes up with a shiny new technology that will solve all our issues, or is just fun to use and gets some attention. Funny enough, the sales guys also want us to use these new tools and technologies, because it is nice to bring them up during sales conversations: “yes we have agile development”, “yes we do devops”, “of course we use continuous integration on Github”, “sure we use C# 5.0”. The fact they do not understand it is irrelevant since their job is selling our product and how they make the deal is not that important (so I don’t blame them), even if it involves showing off with “their” developers that use the latest technology on the market.
Just as Mr. Hariri speech, there is no real point to make in this article so far, but only a take away: if you are applying these new technologies, are you doing it for your own excitement, or, are you actually providing value to the business. You’ll see in this blog I work with a lot of new silver bullets, for example the article on Redis and Docker and NodeJS. It is not my intention to convince you of these technologies and apply them straight away. I write these articles while investigating these new technologies so I can see whether they can add value to my business. I’m only writing it down because maybe some day, somebody, somewhere in the world, saves a little time with it to decide whether or not it adds value to his business as well. And even though I did test Redis on Docker on Windows, I’m quite sure I will not use it in our product, but that doesn’t mean you can’t either, or I will not use it later on in another project when it would be appropriate.
Because just as much as it is your obligation to avoid intellectual masturbation, it is your obligation as a (software) engineer to be on the lookout for new technologies that can bring in more value to the company. You must remain up-to-date and learn new technologies. So go out and investigate the latest tool, but evaluate it correctly and you have a good career coming, else you are just wasting money.
